Building Reliable Applications with Google's Gemini 2.0 Flash
Google has unveiled Gemini 2.0 Flash in December 2024, an experimental AI reasoning model that sets itself apart through transparent reasoning processes (aka. Thinking Mode) and improved problem-solving capabilities.

As a direct competitor to OpenAI's o1 reasoning model, this release signifies Google's push toward more transparent and capable AI models.
Let's take a look at the key capabilities of Gemini 2.0 Flash, how its performance compares to previous models, and how to build a high-performance AI application with Gemini 2.0.
What is Gemini 2.0?
Gemini 2.0 is Google's latest AI model designed to offer developers the tools to build more advanced agentic applications.
| Feature | Specification |
|---|---|
| Input Token Limit | 1 million tokens |
| Output Token Limit | 8K tokens |
| Knowledge Cutoff | August 2024 |
| Input Format | Text, Images, Audio, Video |
| Output Format | Text, Image, Speech |
| Pricing | Free through AI Studio, pay-as-you-go pricing |
Gemini 2.0 brings multimodal capabilities and doubles the speed of its predecessor Gemini 1.5 Pro while being more performative on key benchmarks (more on that later). What distinguishes Gemini 2.0 is its advanced reasoning process, which helps it verify the accuracy of long thought chains and significantly reduces model hallucinations.
What's an agentic application?
An AI system that's capable of executing multi-step tasks on behalf of users. For example, interacting with multiple data sources or tools to achieve user-specified goals.
Key Features of Gemini 2.0
New Multimodal Capabilities
Like previous models, Gemini 2.0 Flash supports multi-modal inputs (text, images, audio and video). The new model now introduced multimodal outputs that allows the generation of responses with text, audio, and images through a single API call, making it a versatile model for a wider range of applications.
Advanced Reasoning = Better Performance
Gemini 2.0's advanced reasoning allows it to analyze complex tasks, think multiple steps ahead, and provide results that are more accurate and context-aware than top models like OpenAI o1. This makes Gemini 2.0 more ideal for use cases where deeper analysis is required, like AI-powered research assistants and complex query handling.
Integration with Native & External Tools
Developers will appreciate the new Multimodal Live API, which allows Gemini 2.0 to integrate in real-time with native tools like Google Search, Maps, and code execution, as well as custom third-party functions via function calling.
This integration makes Gemini 2.0 a valuable tool for tasks that require dynamic, real-time data from multiple sources, such as real-time media analysis or live decision-making based on current data.
Improved Developer Experience
Developers can integrate pretrained models like Gemini 2.0 into their projects easily using Google AI Studio and Vertex AI. Tools like Gemini Code Assist for programming tasks and Google Colab integrations with Gemini's capabilities are examples of how Google is making AI more accessible for developers.
Gemini 2.0 Benchmarks: Performance and Speed
Google’s Gemini 2.0 Flash has been specifically designed for speed and performance. According to early benchmarks, Gemini 2.0 Flash performs twice as fast as its predecessor, Gemini 1.5 Pro, and matches top models like OpenAI o1 and Llama 3.3 70b. Gemini 2.0 also significantly improved time to first token (TTFT) compared to Gemini 1.5 Flash.
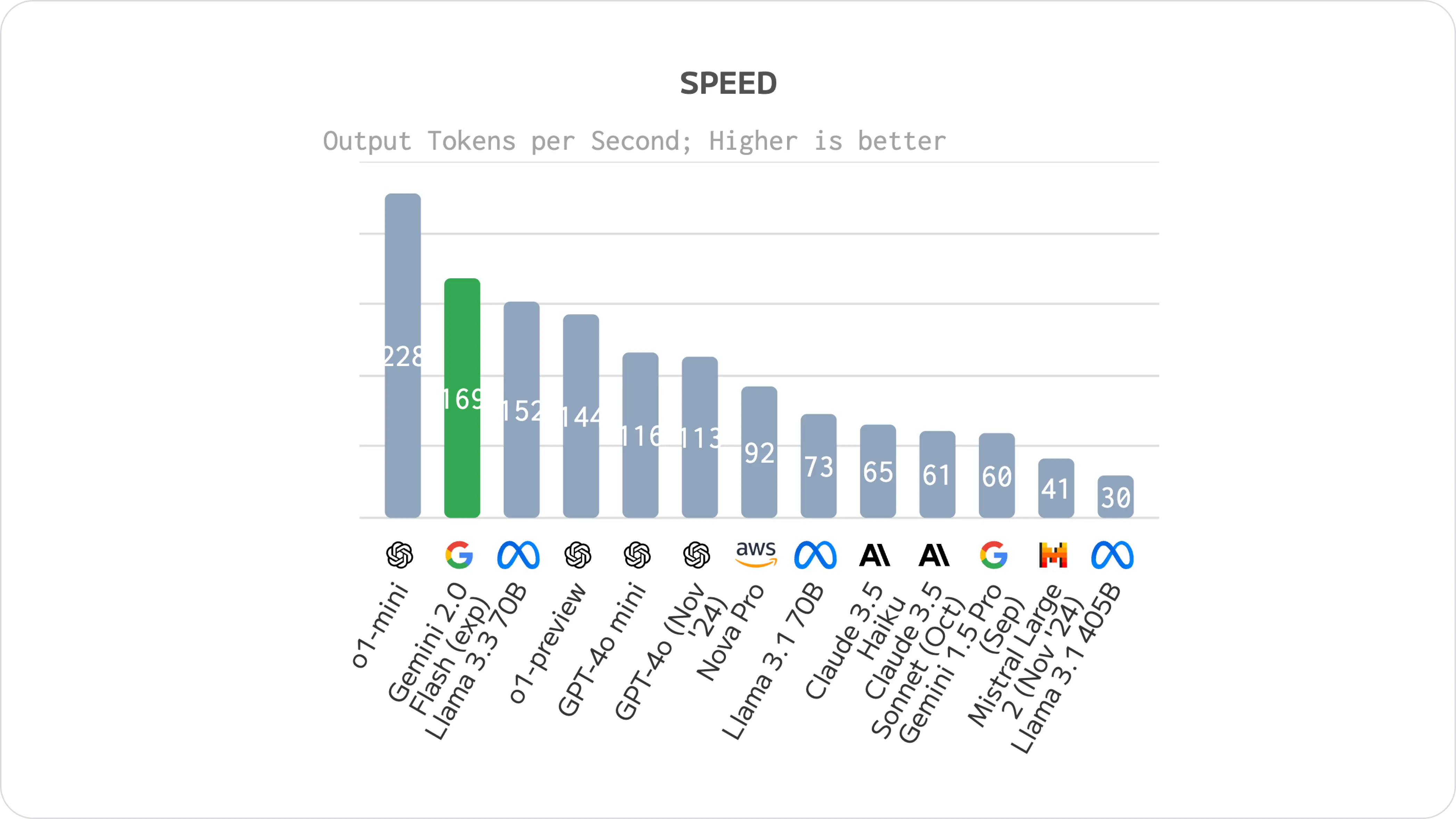
Gemini 2.0 Flash outperforms previous models in terms of handling multiple types of input formats. For example, when tested with multimodal inputs (combining images, text, and audio), Gemini 2.0 showed impressive responsiveness and processing speed, trailing right behind o1-mini.
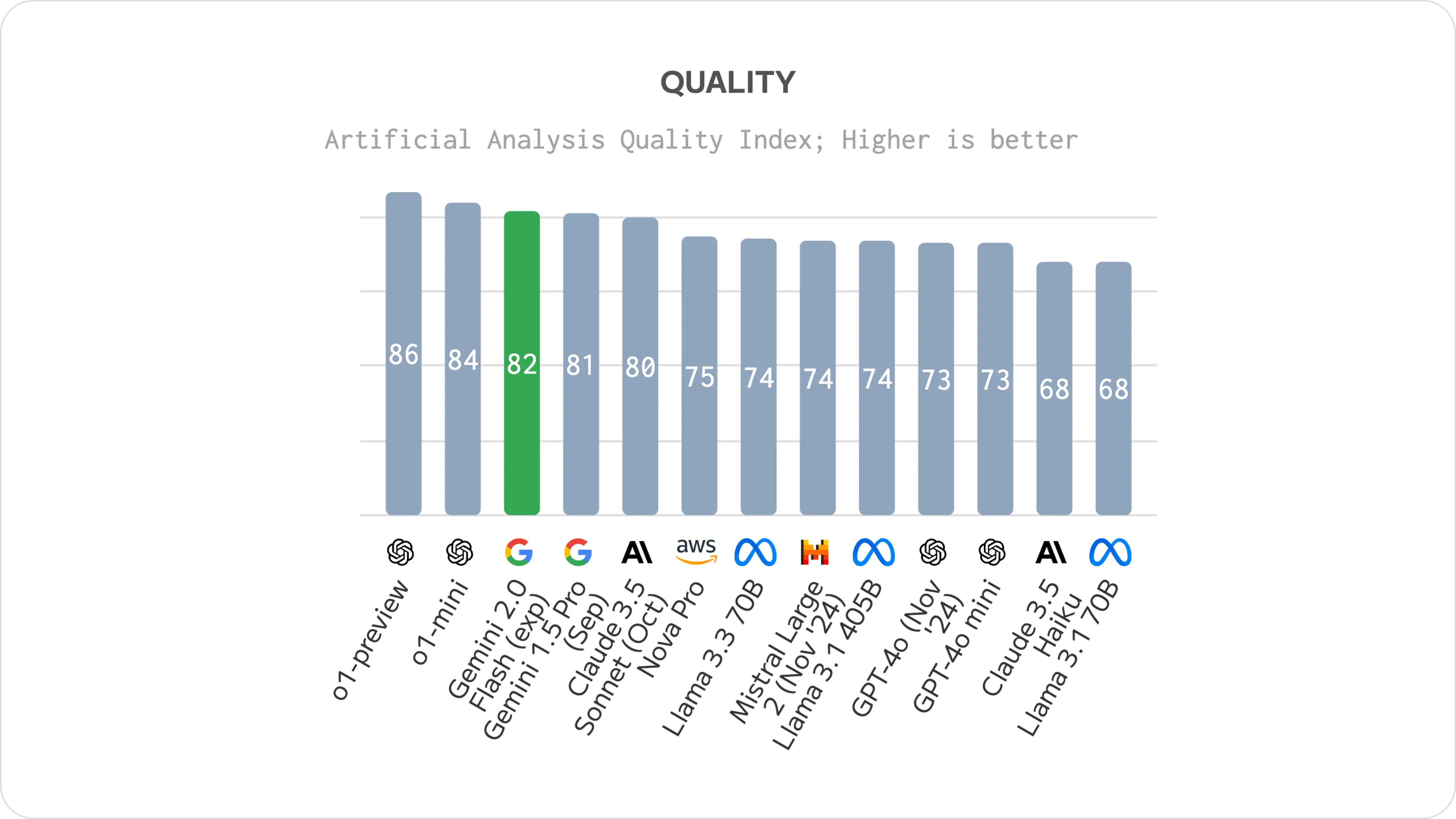
Moreover, Gemini 2.0 is expected to become widely available to users in early 2025. Google has already started limited testing of Gemini 2.0 in AI Overviews for Search in December 2024. The broader rollout of Gemini 2.0 to Google Search and other Google products is planned for early 2025.
How Gemini 2.0 Stacks Up Against Previous Versions
When comparing Gemini 2.0 with previous iterations, there are several notable improvements:
- Speed and Performance: As mentioned, Gemini 2.0 Flash is notably faster than its predecessors, offering improved response times for developers and users.
- Multimodal Support: The added multimodal input and output capabilities sets Gemini 2.0 apart from earlier versions that only handled text.
- Agentic Features: While Gemini 1.0 and 1.5 models could respond to text-based prompts, Gemini 2.0 can handle complex, multi-step tasks autonomously.
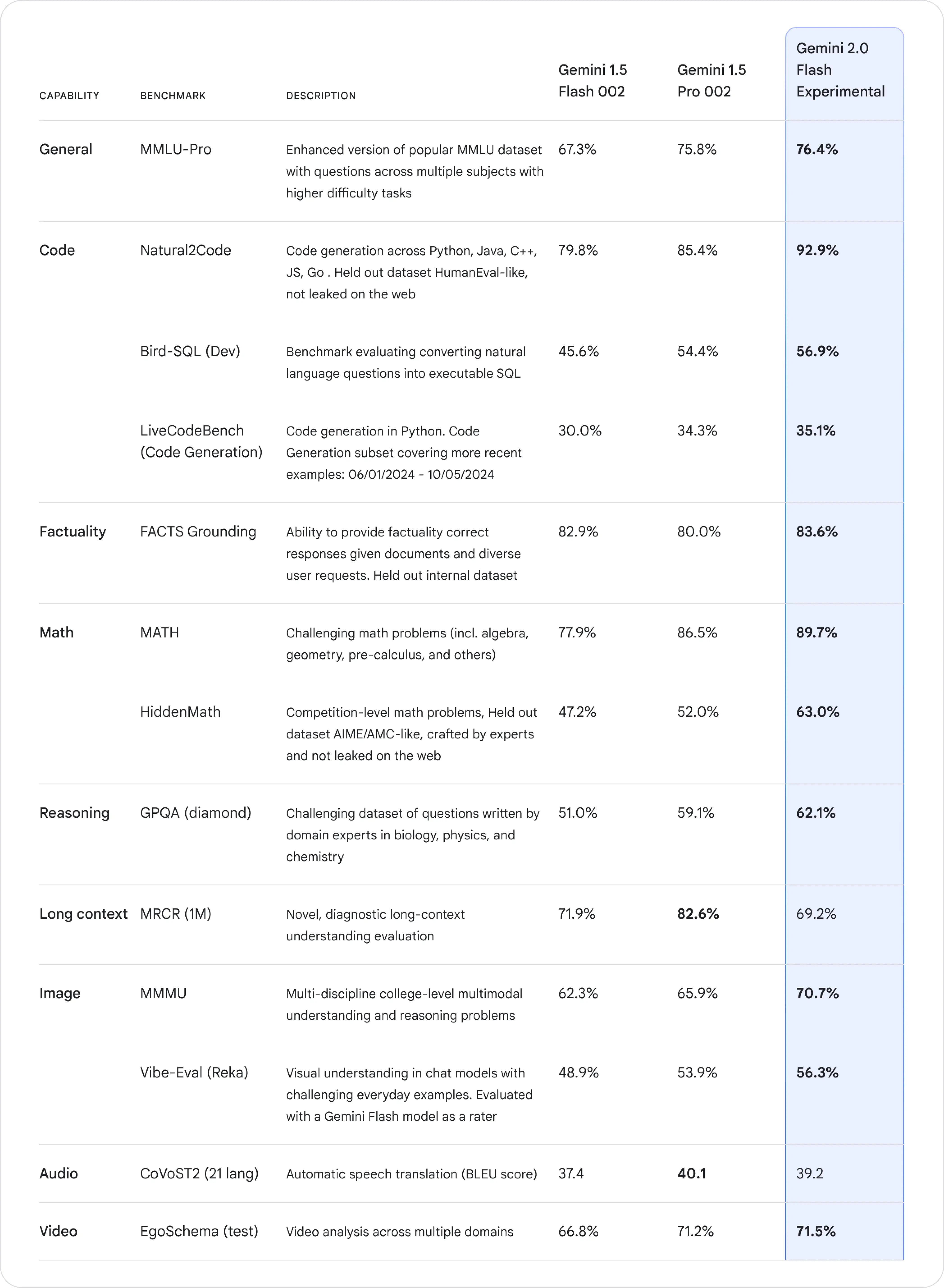
These upgrades make Gemini 2.0 not just a tool for developers but also a potential game-changer in industries like healthcare, finance, and gaming, where decision-making, multi-step reasoning, and real-time data interaction are vital.
How Gemini 2.0 compares with o1 and Claude 3.5 Sonnet
| Benchmark | Gemini 2.0 Flash Experimental | Claude 3.5 Sonnet | OpenAI o1 |
|---|---|---|---|
| MMLU (General knowledge) | 3️⃣ 76.4% (Google) | 88.3% (0-CoT, Anthropic) | 91.8% (OpenAI) |
| LiveBench (Coding average) | 3️⃣ 50.0% (LiveBench) | 67.1% (LiveBench) | 69.7% (LiveBench) |
| Math | 2️⃣ 89.7% (Google) | 71.1% (0-CoT, Anthropic) | 96.4% (OpenAI) |
| MMMU (multi-modal benchmark) | 2️⃣ 70.7% (Google) | 68.3% (0-CoT, Anthropic) | 77.3% (OpenAI) |
| GPQA (Reasoning) | 2️⃣ 62.1% (Google) | 59.4% (0-CoT, Anthropic) | 75.7% (OpenAI) |
Compared to OpenAI and Anthropic's latest models (o1 and Claude 3.5 Sonnet), OpenAI's o1 leads across most benchmarks in highest MMLU score at 91.8%, best math performance and best reasoning capabilities with 75.7% on GPQA.
Gemini 2.0 Flash Experimental trails in general knowledge with 76.4% MMLU, a strong math performance at 89.7% and competitive in multimodal tasks at 70.7% MMMU.
Limitations
People and Image Editing Restrictions
Generating images of people or editing uploaded images of individuals is prohibited. This is to ensure privacy and respect for all users, maintaining a standard of ethics in image creation.
Optimized Language Support
For optimal performance in image generation, it’s best to use specific languages such as English (EN), Spanish (es-MX), Japanese (ja-JP), Chinese (zh-CN), and Hindi (hi-IN). These languages are supported with the highest accuracy and fluency for the best results.
Audio and Video Limitations
Please note that audio or video inputs are not supported for image generation. The focus remains on creating visual content based on textual prompts only.
Image Generation Challenges
Sometimes, image generation might not trigger as expected, and there are a few things you can try:
- If the model outputs text instead of an image, try explicitly asking for an image in your prompt (e.g., “generate an image” or “please provide images as you go along”).
- On some occasions, the model may stop generating an image halfway through. If this happens, kindly attempt the request again or modify your prompt slightly to get the desired output.
Where to Access Gemini 2.0
As of now, an experimental version of Gemini 2.0 is available to developers and trusted testers. Google has already begun integrating it into several of its products and services, including Google Search, and through the Gemini API in Google AI Studio and Vertex AI.
For those interested in exploring Gemini 2.0’s capabilities, Google is offering free access through AI Studio, where developers can experiment with the multimodal live API and other advanced features. Developers can access the model in code by using gemini-2.0-flash-thinking-exp or gemini-2.0-flash-thinking-exp-1219.
Building Reliable LLM Applications with Gemini 2.0
When building an LLM application, it’s important to monitor model outputs to ensure consistent performance for end-users. There are a few ways we recommend:
- Reduce latency in model responses
- Analyze patterns in user behaviors and tailor your prompt accordingly
- Set up systems to detect anomaly in model behaviors before they affect your users
- Set up systems to identify performance bottlenecks in real-time and reduce your debugging time.
Use Helicone’s free dashboard to monitor your model’s response time, latency and costs in real time. Integrating your Gemini app only takes a few seconds and 2 lines of code.
Pricing: Is Gemini 2.0 free or paid?
Free access through AI Studio
An experimental version of Gemini 2.0 Flash Thinking is available at no cost through Google AI Studio, with the limitations of a maximum context window of 32,767 tokens and usage restrictions or 2 requests per minute (RPM) and 50 requests per day (RPD).
Pay-as-you-go pricing
For users requiring more extensive capabilities, Gemini 2.0 Flash offers flexible pay-as-you-go pricing based on token usage.
| Operation | Standard Prompts (Up to 128K tokens) | Extended Prompts (Beyond 128K tokens) |
|---|---|---|
| Input Processing | $0.075 per million tokens | $0.15 per million tokens |
| Output Generation | $0.30 per million tokens | $0.60 per million tokens |
| Context Caching | $0.01875 per million tokens | $0.0375 per million tokens |
| Context Caching Storage | $1.00 per million tokens per hour | $1.00 per million tokens per hour |
What's next for Google's AI?
Looking ahead, Google’s vision for Gemini 2.0 is centered around making AI more "agentic"—being able to take actions on behalf of users. This concept has evolved from previous "assistant" models, where AI was used primarily for answering questions and providing insights. Now with Gemini 2.0, the goal is to create models that can handle more practical, action-oriented tasks, such as planning a trip, completing programming tasks, or interacting with other software tools.
In line with this, Google is developing Project Astra, a research initiative exploring the potential of a universal AI assistant. Similar to J.A.R.V.I.S. from the Iron Man films, this assistant would be able to understand a vast array of contexts, handle complex tasks, and assist users in real-time.
Other models you might be interested in
- Google - Gemini-Exp-1206
- OpenAI - o1 & ChatGPT Pro
- Meta - Llama 3.3 70b Instruct
Questions or feedback?
Are the information out of date? Please raise an issue and we’d love to hear your insights!